
ZFS est un système de fichiers développé par Sun, pour son OS : Solaris. La première release stable date de juin 2006. Depuis, celui-ci a été adapté d’abord à FreeBSD, puis plus récemment à NetBSD et à Linux. Aujourd’hui, ZFS est disponible dans les dépôts officiels d’Ubuntu depuis la version 15.10. Il souffre néanmoins d’une popularité plus restreinte sous Linux, car son intégration au sein du noyau est impossible à cause d’une incompatibilité de licence. Un projet similaire nommé Btrfs est censé pallier à ce problème juridique, malheureusement, cette seconde solution reste moins avancée que ne l’est ZFS pour le moment.
ZFS se distingue des systèmes de fichier plus traditionnels tel que EXT4 par son lot de fonctionnalités annexes au stockage en lui-même, comme la gestion des disques, l’optimisation de l’espace, l’exportation des données, la création de sauvegardes et de leurs restaurations, ou encore les performances avec des caches en RAM. Je vous propose de faire un rapide tour de ces différents services.
Des disques physiques aux partitions logiques
ZFS distingue les disques réels permettant de stocker physiquement la donnée et son équivalent virtuel que l’on montera depuis le système d’exploitation. Plus précisément, on parlera de datasets présents dans des zpools, composés de plusieurs vdev (virtual devices) représentant eux-même les disques concrets. On a donc une hiérarchie à trois ou quatre niveaux dans l’élaboration d’un seul point de montage, car les datasets sont facultatifs. Pour mieux comprendre, voici un exemple :
Nous avons quatre disques durs, de 1 Go chacun. On va les utiliser de telle façon à avoir un pool de stockage de 2 Go répliqués :
# zpool create tank mirror /home/spydemon/hdd1 /home/spydemon/hdd2 mirror /home/spydemon/hdd3 /home/spydemon/hdd4
# zpool status
pool: tank
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
/home/spydemon/hdd1 ONLINE 0 0 0
/home/spydemon/hdd2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
/home/spydemon/hdd3 ONLINE 0 0 0
/home/spydemon/hdd4 ONLINE 0 0 0
errors: No known data errors
# sudo zfs list
NAME USED AVAIL REFER MOUNTPOINT
tank 56,5K 1,95G 19K /tank
Nous pouvons à présent directement exploiter le zpool /tank, ou alors le segmenter en différents datasets. L’avantage de cette seconde technique est de pouvoir appliquer des réglages différents en fonction des cas, par exemple, imposer des quotas maximums d’utilisation d’espace disque.
# zfs create dataset /tank/dataset1 # zfs create dataset /tank/dataset2 # zfs set quota=50M tank/dataset1 # dd if=/dev/zero of=/tank/dataset1/test bs=1M count=60 dd: erreur d'écriture de «/tank/dataset1/test»: Débordement du quota d'espace disque 51+0 enregistrements lus 50+0 enregistrements écrits 52428800 octets (52 MB) copiés, 2,67 s, 19,6 MB/s # zfs list NAME USED AVAIL REFER MOUNTPOINT tank 50,4M 1,90G 19K /tank tank/dataset1 50,0M 0 50,0M /tank/dataset1 tank/dataset2 19K 1,90G 19K /tank/dataset2
Voici un schéma pour mieux comprendre :
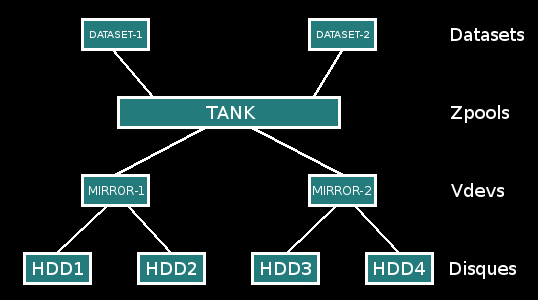
Comme nous pouvons le voir à l’aide des commandes précédentes, nous avons conçu deux vdevs : mirror-0 et mirror-1 appartenant tous les deux au zpool tank dont la taille efficace est de 2 Go. Il est monté sur /tank dans l’arborescence (en gros, touch /tank/file.txt nous permet de créer un fichier file.txt sur notre réserve ZFS).
Notez que nous pouvons à chaud rajouter des disques aux vdevs, des vdevs aux pools, mais que l’on ne peut jamais en retirer. Il est aussi bon de préciser qu’à la perte d’un seul vdev, c’est tout le pool qui est en général détruit. Il faut donc être prudent dans la conception de l’infrastructure, car la sécurité de l’ensemble de la chaîne dépendra toujours du maillon le plus faible.
Transporter les données
Nos pools peuvent être assez facilement changés de serveur. Nous pouvons par exemple effectuer un zpool export tank pour « démonter » notre fichier, ce qui nous autorise le débranchement des disques durs physiques correspondant pour les remettre ailleurs. Il nous suffira d’exécuter un zfs import tank pour retrouver notre système de fichier parfaitement opérationnel.
Remplacer un disque cassé
Comme les disques durs sont loin d’être immortels, il arrivera forcément à moment ou l’autre un problème sur notre infrastructure :
# zpool status tank -x
pool: tank
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: http://zfsonlinux.org/msg/ZFS-8000-4J
scan: scrub repaired 0 in 2h4m with 0 errors on Sun Jun 9 00:28:24 2013
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
sda ONLINE 0 0 0
sdb UNAVAIL 0 0 0
mirror-1 ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
errors: No known data errors
Comme nous le voyons, /dev/sdb vient de décéder. Pour pouvoir effectuer le dépannage, il suffira de trouver le disque exact depuis, par exemple, son numéro de série (la commande hdparm peut aider), de physiquement le débrancher, d’insérer son remplaçant, et d’exécuter zpool replace tank sdb sdb pour changer l’ancien média sdb par le nouveau, au même emplacement.
# zpool replace tank sdb sdb
# zpool status tank
pool: tank
state: ONLINE
status: One or more devices is currently being resilvered. The pool will
continue to function, possibly in a degraded state.
action: Wait for the resilver to complete.
scrub: resilver in progress for 0h2m, 16.43% done, 0h13m to go
config:
NAME STATE READ WRITE CKSUM
tank DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
replacing DEGRADED 0 0 0
sda ONLINE 0 0 0
sdb ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
ZFS se chargera lui-même de resynchroniser le nouveau disque avec les données redondées.
Versionnage des données
Peut-être que le mot « versionnage » est un peu fort, car nous n’avons pas les mêmes possibilités que nous offre un vrai gestionnaire de version (comme Git), mais en utiliser un autre tel que « rollback » ou encore « copie » aurait été trop réducteur.
En effet, ZFS implémente un système d’instantané qui nous permet en moins d’un centième de seconde de faire une copie de tout un dataset. De plus, sa taille est nulle à la création, et prendra du poids au fur et à mesure de l’évolution de celui-ci.
Pour faire un instantané, il nous suffit d’utiliser la commande :
zfs snapshot tank/test@tuesday.
Ici, on effectue un instantané de notre dataset test sur le pool tank, qu’on appelle tuesday. La première utilité qu’on voit à un tel système est bien sûr de nous permettre de faire des réinitialisations en cas de problème. Si par exemple le mercredi suivant, la base de données de notre site se corrompt et devient inutilisable, un simple roolback nous permettra de revenir dans l’état de mardi :
zfs rollback tank/test@tuesday.
Mais en plus de ça, un instantané peut être cloné et monté en écriture ailleurs, permettant ainsi d’avoir pour un même dataset, plusieurs versions de celui-ci en cours d’utilisation :
zfs clone tank/test@tuesday tank/tuesday.
De cette façon, en plus d’avoir accès à /tank/test au niveau de notre arborescence, nous avons un /tank/tuesday qui a initialement le même contenu qu’avait /tank/test au moment du snapshot. Bien sûr, seuls les blocks qui différeront seront réellement écrits sur le disque, ce qui encore une fois fera pas mal d’économie de taille.
Quelle pourrait être l’utilité d’avoir plusieurs datasets possédant tous une base commune ? Imaginez devoir gérer un serveur d’intégration, permettant de tester les évolutions en cours de création sur un site Web donné. Il arrive fréquemment d’en développer plusieurs en simultané, ce qui impose à notre unique machine beaucoup de redéploiements. Malheureusement, les adaptations effectuées à la base de données par la fonctionnalité X posent régulièrement problème quand le code de celle-ci n’est plus présent, car c’est maintenant au tour d’Y d’être en démonstration… Résultat ? Changer l’intégration de branche signifie souvent réinitialiser la base de données, ce qui est bien plus long qu’un simple git checkout fonctionnalité-Y.
Versionner cette base de données nous permet de faire en sorte que chaque évolution reste cloisonnée avec ses modifications.
Notre pool sql pourrait avoir un dataset base correspondant à la base de données après importation de celle de production, et deux clones de celle-ci func-X et func-Y représentant leurs différences propres. Il suffirait donc à présent de changer la configuration de notre SGBD pour qu’en fonction de la branche en intégration, on utilise un répertoire ou l’autre, sans que plus jamais nous n’ayons d’interférences. 🙂
Pour la réalisation de backups, on peut très facilement exporter un snapshot ailleurs à l’aide de la sous-commande send, et même de le remonter de façon totalement transparente avec receive. Exécuter :
zfs send tank/test@tuesday | ssh user@backup.example.com "zfs receive pool_backup/tuesday"
et mettre pool_backup/tuesday en lecture seule est un exemple nous permettant d’avoir un système simple et efficace de sauvegarde avec visualisation du contenu.
Optimisation de l’espace disque
ZFS nous offre deux techniques permettant d’économiser de l’espace disque : la compression et la déduplication. Cette première devrait vous dire quelque chose, car il ne s’agit ni plus ni moins que la même compression présente partout ailleurs. La différence vient du fait que dans le cas présent, elle est totalement transparente pour l’utilisateur : il n’en a aucunement conscience : le fichier restera considéré comme normal pour le système d’exploitation, il sera juste plus léger.
Pour l’activer, il nous suffit d’exécuter la commande suivante :
zfs set compression=on tank. Les performances sont assez significatives. Bien sûr, le ratio d’efficacité dépendra directement de la nature de la donnée à écrire (si celle-ci a déjà été compressée, le gain sera forcément nul), mais la charge processeur engendrée est presque inexistante. À titre d’exemple, une base de données sur pool non compressée me prenait 4,43Go, contre 1,47Go dans l’autre cas, pour un temps de traitement identique.
La seconde solution se situe au niveau de la déduplication. Le principe consiste à ne pas répéter plusieurs fois sur les disques une information égale, mais de pointer vers une unique copie. C’est par exemple très pratique dans le cas de machines virtuelles basées sur le même système d’exploitation. Imaginons avoir besoin de cinq hôtes Debian, dont l’image de base fait 200Mo. Sans déduplication, 1Go aurait été écrit, contre un peu plus de 200Mo avec : l’image commune, plus les quelques différences de configuration et de paquets installés sur chaque VM spécifiquement. Encore une fois, l’opération est totalement transparente pour l’utilisateur.
Attention cependant, car la déduplication est un procédé bien lourd. Elle nécessite une très grande quantité de RAM pour fonctionner correctement (on conseille jusqu’à 20Go de RAM pour dédupliquer 1To), ou alors d’avoir un cache de lecture rapide et gros (le mettre sur un SSD, par exemple). Si vous voulez néanmoins en profiter, il nous suffit de l’activer de façon aussi simple que pour la compression :
zfs set dedup=on tank
Le mot de la fin
Pas mal de fonctionnalités plus avancées ont été omises dans cette introduction, comme les différents caches (SLOG, ARC, ARC2L), le chiffrement, les zvols, des choses concernant la récupération après un sinistre, la multitude de variables de configuration ou de monitoring de disponibles, ou encore certains aspects plus techniques comme le copy-on-write, et tous les types de RAIDZ. Malgré tout, vous devriez avoir un tour d’horizon à présent assez grand pour, au moins, pouvoir appréhender ZFS et jouer un peu avec pendant vos heures perdues. Bien entendu, si l’envie vous prend de pousser plus loin votre investigation dans le domaine, vous trouverez une abondance d’informations sur Internet. Je vous conseille d’ailleurs l’excellent dossier qu’a fait Aaron Toponce à cet égard.
Crédit image :
- Le disque dur en couverture par sinusdigital
Publication originale :
Cet article a été publié initialement sur le blog Netapsys.
![]()